Стохастические критерии (класс III)
Стохастическое тестирование применяется при тестировании сложных программных комплексов - когда набор детерминированных тестов (X,Y) имеет громадную мощность. В случаях, когда подобный набор невозможно разработать и исполнить на фазе тестирования, можно применить следующую методику.
- Разработать программы - имитаторы случайных последовательностей входных сигналов {x}.
- Вычислить независимым способом значения {y} для соответствующих входных сигналов {x} и получить тестовый набор (X,Y).
- Протестировать приложение на тестовом наборе (X,Y), используя два способа контроля результатов:
- Детерминированный контроль - проверка соответствия вычисленного значения yв{y} значению y, полученному в результате прогона теста на наборе {x} - случайной последовательности входных сигналов, сгенерированной имитатором.

Стохастический контроль - проверка соответствия множества значений {yв}, полученного в результате прогона тестов на наборе входных значений {x}, заранее известному распределению результатов F(Y).
В этом случае множество Y неизвестно (его вычисление невозможно), но известен закон распределения данного множества.
- Детерминированный контроль - проверка соответствия вычисленного значения yв
Критерии стохастического тестирования
- Cтатистические методы окончания тестирования - стохастические методы принятия решений о совпадении гипотез о распределении случайных величин. К ним принадлежат широко известные: метод Стьюдента (St), метод Хи-квадрат (?2) и т.п.
- Метод оценки скорости выявления ошибок - основан на модели скорости выявления ошибок [12], согласно которой тестирование прекращается, если оцененный интервал времени между текущей ошибкой и следующей слишком велик для фазы тестирования приложения.
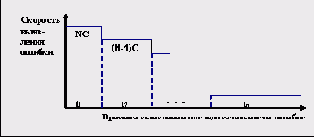
Рис. 3.1. Зависимость скорости выявления ошибок от времени выявления
При формализации модели скорости выявления ошибок (рис. 3.1) использовались следующие обозначения:
N - исходное число ошибок в программном комплексе перед тестированием,
C - константа снижения скорости выявления ошибок за счет нахождения очередной ошибки,
t1,t2,…tn - кортеж возрастающих интервалов обнаружения последовательности из n ошибок,
T - время выявления n ошибок.
Если допустить, что за время T выявлено n ошибок, то справедливо соотношение (1), утверждающее, что произведение скорости выявления i ошибки и времени выявления i ошибки есть 1 по определению:
(1) (N-i+1)*C*ti = 1 В этом предположении справедливо соотношение (2) для n ошибок:
(2) N*C*t1+(N-1)*C*t2+…+(N-n+1)*C*tn=n N*C*(t1+t2+…+tn) - C*?(i-1)ti = n NCT - C*?(i-1)ti = n Если из (1) определить ti и просуммировать от 1 до n, то придем к соотношению (3) для времени T выявления n ошибок
(3) ?1/(N-i+1) = TC Если из (2) выразить C, приходим к соотношению (4):
(4) C = n/(NT - ?(i-1)ti) Наконец, подставляя C в (3), получаем окончательное соотношение (5), удобное для оценок:
(5) ?1/(N-i+1) = n/(N - 1/T*?(i-1)ti) Если оценить величину N приблизительно, используя известные методы оценки числа ошибок в программе [2], [13] или данные о плотности ошибок для проектов рассматриваемого класса из исторической базы данных проектов, и, кроме того, использовать текущие данные об интервалах между ошибками t1,t2…tn, полученные на фазе тестирования, то, подставляя эти данные в (5), можно получить оценку tn+1 -временного интервала необходимого для нахождения и исправления очередной ошибки (будущей ошибки).
Если tn+1>Td - допустимого времени тестирования проекта, то тестирование заканчиваем, в противном случае продолжаем поиск ошибок.
Наблюдая последовательность интервалов ошибок t1,t2…tn, и время, потраченное на выявление n ошибок T=?ti, можно прогнозировать интервал времени до следующей ошибки и уточнять в соответствии с (4) величину C.
Критерий Moranda очень практичен, так как опирается на информацию, традиционно собираемую в процессе тестирования.